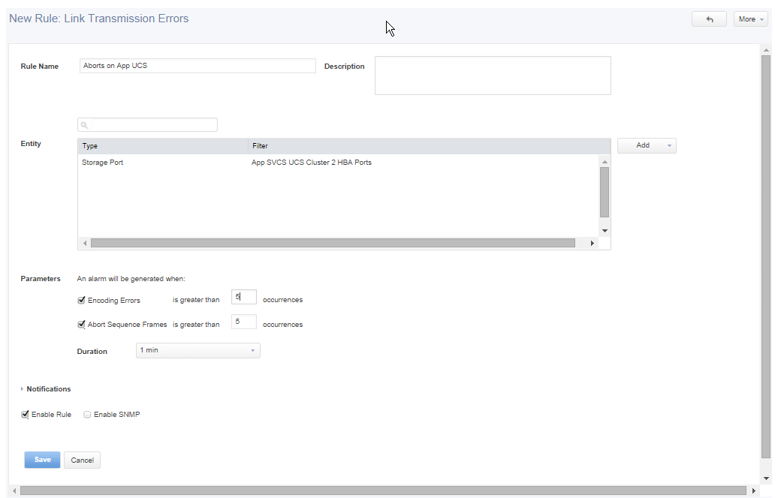
Excessive Aborts
What is an Abort?
An Abort is the generation of an Abort Sequence (ABTS) Fibre Channel Frame by a host, in order to terminate a sequence or exchange that has either timed out or encountered physical layer errors. It is the main method of recovery from frame-level and sequence-level errors.
Why are Excessive Aborts a Problem?
An Abort indicates a significant communication problem, such as lost or dropped frames, CRC and other framing errors, lack of credit or unexpected resets and reboots. An excessive number of Aborts usually indicates a persistent problem, such as a failing HBA, continually rebooting server, inaccessible device or problematic connection (faulty cabling, SFPs or patch panels). Each Abort forces the Initiator to take appropriate steps to either retry or terminate the exchange. Depending upon the devices involved, recovery from an Abort could take anywhere from milliseconds to a minute or more. This can cause a very serious performance impact.
Required to identify : SAN Performance Probe hardware.
What are Common Causes of Excessive Aborts?
An Abort can be caused by:
- Dropped frames resulting in out-of-order delivery of data
- Dropped frames resulting in a SCSI timeout (server-side configurable timeout value usually set to 5-60 seconds)
- No frames for a transaction
- CRC, Frame and Encoding Error in frames or sequences
- Lack of buffer-to-buffer credit
- Unexpected device resets and reboots
- Timeout due to a sequence taking longer to complete than the Resource Allocation Timeout Value (R_A_TOV) or the Error Detect Timeout Value (E_D_TOV)
Excessive Aborts are likely to be caused by a persistent condition, such as a:
- Failing HBA
- Continually rebooting server or target
- Problematic connection (due to faulty cabling, SFPs or patch panels)
- Device which has become inaccessible for some other reason
How to Spot an Abort; Correlating Aborts with Other Events
The SAN Performance Probe keeps track of the number of Abort Sequence Frames which have occurred on a link. This information can be viewed in the Live Reports under Analysis:
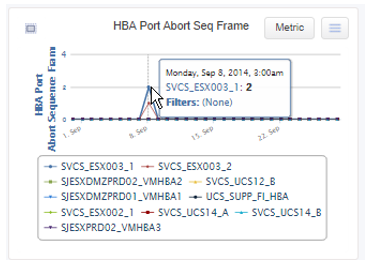
Aborts in the presence of:
- Class 3 Discards are likely due to dropped frames or lack of buffer-to-buffer credit
- CRC, Frame or Encoding Error, Loss of Sync events or Loss of Signal events are likely due to a problematic connection (see Live Report Below)
- Link Resets or Link Failures are likely due to unexpected device resets or reboots
- Spikes in Exchange Completion Times (ECTs) are likely due to timeouts
For example, here we see Aborts in the presence of CRC Errors, along with Encoding Errors and other types of Frame Errors:

How to Resolve Excessive Aborts
The best approach to resolve Excessive Aborts is to identify what is directly causing the Aborts, for example Encoding Errors and, then identify the root cause for example a faulty cable.
The easiest cause to start with may be a server reboot or cable alteration. These will occur from time to time with the moving of equipment or configuration changes. In those cases, corresponding change control log entries should always exist.
If the change control log does not indicate any intentional reboot, reconfiguration or other manipulation of equipment, cables or SFPs, there could be actual physical problems with the optics. Resolving Excessive Aborts may require examining, testing, cleaning and/or replacing SFPs, cables or patch panels until the issues cease. In some cases, an HBA may need to be replaced as well.
Ongoing Monitoring
Aborts should be rare events in an enterprise SAN, therefore alarms should be set to detect and alert on any of them. The level of urgency in resolving them may depend upon the location (storage link or host link) or the particular application they are impacting. The most efficient approach is to resolve the existing Aborts quickly and then set up alarms. Set up alarms for each type of location:
- Storage link
- Host link
You may also want to create specific alarms for high-priority applications to ensure the correct level of urgency is applied. Ideally the alarm thresholds should be set to “>0.” This means alarming on the occurrence of any Abort. Initially however, it may be best to set them to alarm if a certain number of Aborts occur within a time period, to address the worst-behaving links first. Be sure to adjust the alarms as soon as the initial Aborts are resolved.